Indexing Rewards¶
General¶
Indexer have a vital role to fulfill in The Graph ecosystem. This role is incentivized by two revenue streams for indexers. On the one hand, indexers are rewarded for their service in the ecosystem by receiving payments for serving queries in the networ (query fee rebates). And on the other hand, the 3% annual protocol-wide inflation is distributed to indexers who index subgraphs in the network. This second revenue stream are the indexing rewards. See The Graph documentation for further information.
Indexing rewards come from protocol inflation which is set to 3% annual issuance. They are distributed across subgraphs based on the proportion of all curation signals on each, then distributed proportionally to indexers based on their allocated stake on that subgraph. An allocation must be closed with a valid proof of indexing (POI) that meets the standards set by the arbitration charter to be eligible for rewards. -- FAQ on The Graph Documentation:
Equation¶
Allocations are therefore a core aspect of The Graph ecosystem for indexers to earn indexing rewards. Based on the distribution and the amounts of allocations on different subgraphs, the indexing rewards are calculated using this formula:
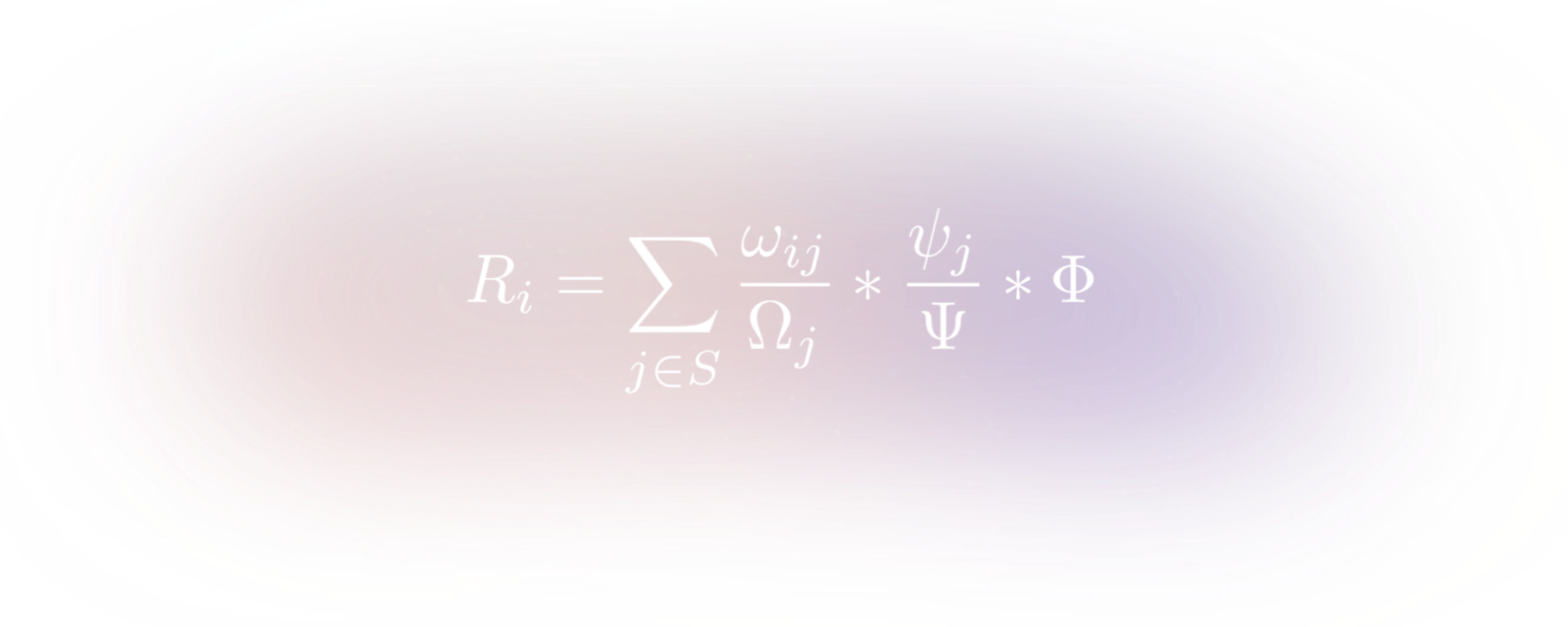 where ωij is the amount that Indexer i has staked on subgraph j, Ωj is the total amount staked on subgraph j, ψj is the amount of GRT signaled for subgraph j, Ψ is the total amount signaled in the network and Φ is the total network indexer reward denominated in GRT.
where ωij is the amount that Indexer i has staked on subgraph j, Ωj is the total amount staked on subgraph j, ψj is the amount of GRT signaled for subgraph j, Ψ is the total amount signaled in the network and Φ is the total network indexer reward denominated in GRT.
One could now calculate the indexing reward manually for each subgraph and distribute its stake accordingly. An alternative to this would be to define a rule that the indexer agent uses to distribute the allocations automatically. For example, one could distribute the stake equally among all subgraphs in the network. However, this might lead to not getting the optimum indexing reward.
 (Source: Discord stake-machine#1984)
(Source: Discord stake-machine#1984)
Problem Statement: How can indexing rewards be maximized so that the stake of indexers can be used most effectively without the time investment going to the extreme?
Optimizing Indexing Rewards¶
Since this manual approach does not yield the optimal rewards, we use the Grant to develop a tool that computes the optimal allocation distribution using optimization algorithms. The relevant data for calculating the optimal allocation distribution is fetched using the network subgraph and other data sources and fed into the linear optimization model. This model then calculates the optimal distribution of allocations on the different subgraphs, taking into account the preferences and parameterizations of the indexer.
The equation for calculating the indexing rewards is a perfect example of a linear optimization problem. The equation calculates the indexing rewards for each subgraph on which the indexer has an allocation. The sum of the indexing rewards per subgraph gives the total indexing rewards of the indexer.
This tool optimizes the result of this calculation. The goal is to maximize the indexing rewards. So the value that is left in the formula (Ri). For this purpose the variable ωij, i.e. the allocations are optimized. The objective of the optimization is to maximize the indexing rewards. Thereby different constraints are considered.
- The total allocations must not exceed the value of the indexer total stakes (minus the reserve stake).
- For each subgraph that is optimized, the variable allocation must not be less than the min_allocation (parameter).
- For each subgraph that is optimized, the variable allocation must not exceed the max_percentage (parameter) multiplied by the indexer total stake.
For a programmatic explanation, look at this following code:
data = {(df.reset_index()['Name_y'].values[j], df.reset_index()['Address'].values[j], df['id'].values[j]): {
'Allocation': df['Allocation'].values[j],
'signalledTokensTotal': df['signalledTokensTotal'].values[j],
'stakedTokensTotal': df['stakedTokensTotal'].values[j],
'SignalledNetwork': int(total_tokens_signalled) / 10 ** 18,
'indexingRewardYear': indexing_reward_year,
'indexingRewardWeek': indexing_reward_week,
'indexingRewardDay': indexing_reward_day,
'indexingRewardHour': indexing_reward_hour,
'id': df['id'].values[j]} for j in set_J}
# Initialize Pyomo Variables
C = data.keys() # Name of Subgraphs
model = pyomo.ConcreteModel()
S = len(data) # amount subgraphs
model.Subgraphs = range(S)
# The Variable (Allocations) that should be changed to optimize rewards
model.x = pyomo.Var(C, domain=pyomo.NonNegativeReals)
# formula and model
model.rewards = pyomo.Objective(
expr=sum((model.x[c] / (data[c]['stakedTokensTotal'] + sliced_stake)) * (
data[c]['signalledTokensTotal'] / data[c]['SignalledNetwork']) * data[c][reward_interval] for c in
C), # Indexing Rewards Formula (Daily Rewards)
sense=pyomo.maximize) # maximize Indexing Rewards
# set constraint that allocations shouldn't be higher than total stake- reserce stake
model.vol = pyomo.Constraint(expr=indexer_total_stake - reserve_stake >= sum(
model.x[c] for c in C))
model.bound_x = pyomo.ConstraintList()
# iterate through subgraphs and set constraints
for c in C:
# Allocations per Subgraph should be higher than min_allocation
model.bound_x.add(model.x[c] >= min_allocation)
# Allocation per Subgraph can't be higher than x % of total Allocations
model.bound_x.add(model.x[c] <= max_percentage * indexer_total_stake)
# set solver to glpk -> In Future this could be changeable
solver = pyomo.SolverFactory('glpk')
solver.solve(model, keepfiles=True)